統計学実践ワークブック 第15章 確率過程の基礎 p.119 計数過程としての表現のお気持ちを理解する
理解したいこと
- ①ある繰り返し起こるイベントに対してn番目の発生時刻を
とみれば、
は時刻tまでに起こるイベントの回数を表す確率過程とみなせる。
- ②
①のお気持ちをくしゃみを通じて理解する
- ある繰り返し起こるイベント → くしゃみ
- k番目の発生時刻 → k回目のくしゃみが出た時刻
- ここで k = 5 、 t = 11:00 とすると
は、11:00までに合計くしゃみ回数が5回となったことを表している。
11:00 は、5回目のくしゃみが出た時刻が11:00だということを表している。
- 疑問)11:00は確かに時刻であるが数学的な表記としては微妙なのでは?
- 回答)適当な日付(例:2022-03-28)を時刻に添えてからunix epoch time に脳内変換すれば時刻は整数となるので、そういう風に解釈すればよし。
計数過程と正値確率変数列の読み替え
- 日本語訳:「時刻tまでの合計イベント回数がk回以上であること」と「k回目のイベント発生時刻が時刻t以前であること」は同じ(事象を別の視点で述べている)
- 具体例:11:00までに合計くしゃみ回数が5回以上であること vs 5回目のくしゃみは11:00までに発生している
- 具体例の深掘り:11:00までに合計くしゃみ回数が5回以上である、ということは10:45に合計くしゃみ回数は5回でその後6回目を10:46、7回目を10:59といったイベントを、「11:00までに合計くしゃみ回数が5回以上である」という文章は含んでいる。
②を理解したいのでお気持ちを読み取る
 を直接求めないのはなぜ?
を直接求めないのはなぜ?
それを知るために計算しているから。p.119の上にはポアソン分布に従う、と書いてある。p.119の中段以降はこれを導出するための式の羅列である。p.120あたりでガンマ分布をガシガシ計算することでポアソン分布になることが書いてある。なので結論だけ知りたいのであれば途中の式はスルーしても良いかもしれない。
なぜ
と引き算しているのか
- まず、確率変数列Tは指数分布をごにょごにょしてガンマ分布に従うらしい。指数分布もガンマ分布も連続型確率分布であるため、確率変数が範囲ではなく1点を取る確率は0となる。たとえばXが標準正規分布に従う確率変数であるとして、X = 2となる確率は0であることと似た理屈である。ということで、確率変数列Tに注目すると等号ではなく不等号が現れそうな気配が感じ取れる。
- 次に、確率を引き算するときは包含関係が隠れている可能性があって、包含関係のうち共通部分を差し引いているかもしれない(直感)
- くしゃみの例で言えば、
- 11:00に合計くしゃみ回数が5回である
- を
- 5回目のくしゃみをした時刻が11:00以前である
- 6回目のくしゃみをした時刻が11:00以前である
- の二つを駆使して、 11:00までに合計くしゃみ回数が5回であるを表している、と見れば良い。
- くしゃみの例で言えば、
- 図示すると以下である。



統計学実践ワークブック 第12章 一般の分布に関する検定法 p.92 の尤度比検定を用いる場合の棄却域 を導出する
母比率の検定に関する話題で統計学実践ワークブックp.91は二項分布から話が始まる。そしてp.92にて尤度比検定の話となるが、導出過程は書いていなかったので自力で導出してみることにした。なお以下、二項分布ではなくベルヌーイ分布を用いるのは計算のしやすさとわかりやすさからである。
ベルヌーイ分布に従うn個の確率変数から最尤推定量を求める
尤度関数を立式する
は独立にベルヌーイ分布
に従う確率変数であるとする。
は確率θで1を確率1-θで0の値を取る。このとき尤度関数は
となる但し
である。
尤度関数を変形すると、
が得られる( )。
最尤推定量を求める
さてここで最尤推定量を求めたいので、
- 尤度関数の対数すなわち対数尤度関数
を
で偏微分し
- それを0とおいたものを
という手順を踏もう。
対数尤度関数
対数尤度関数をθで偏微分
対数尤度関数をθで偏微分 = 0 をθについて解く
となって、最尤推定量 を得る。
尤度比のお気持ち
今回のポイントはここである。

尤度比は
:帰無仮説のもとでの尤度関数の最大値
:対立仮説のもとでの尤度関数の最大値
を使って、
と表される統計量である。正確性を『超』度外視すれば*1、
を使って、
となる。
実際に尤度比を求めてみる
尤度比から対数尤度比の2倍(逸脱度)を求める
対数尤度比の2倍: は 逸脱度*2 という名前がついているらしい。では以下にて逸脱度を計算すると、
ここで、 より
となってp.92 の尤度比検定を用いる場合の棄却域を得ることができた。
統計学実践ワークブック 第12章 一般の分布に関する検定法 問12.2の[4] あてはまりのよさ について
やること
統計学実践ワークブック 第12章 一般の分布に関する検定法 問12.2の[4] あてはまりのよさ について考えてみる。
情報整理
得られたデータについて
図示
赤がA(まとめる前)で、青がB(まとめた後)のカイ二乗分布で、塗りつぶし部分がP-値の範囲である。(赤塗りつぶしがおよそ0.05で、青塗りつぶしがおよそ0.8)

カイ二乗分布上側確率表
| 自由度 \ 上側確率 | 0.025 | 0.05 | 0.10 | 0.5 | 0.8 |
|---|---|---|---|---|---|
| 9 | 19.02 | 16.92 | 14.68 | 8.34 | 5.38 |
| 5 | 12.82 | 11.07 | 9.23 | 4.35 | 2.34 |
結果の比較
適合度検定の帰無仮説は「観測度数が期待度数に適合している」である。したがって、
- 帰無仮説を棄却する
- 「観測度数が期待度数に適合している」とは言えない
- 帰無仮説を棄却するに足るデータが得られた
- 適合していない
- 当てはまっていない
- 帰無仮説を棄却しない
- 「観測度数が期待度数に適合している」と言えないこともない
- 帰無仮説を棄却するに足るデータが得られなかった
- 適合していることは棄却しない
- 当てはまっている
と結論づけたい(よくある言い回しのまとめ、願望)。
以上を考えると、P-値が大きい方が(ある有意水準から導出される棄却域に入っていないという意味では)比較的あてはまりがよいと思われる。結果、B)まとめた後の方が(今回の問題で言えばパラメータλ=2.99のポアソン分布に)比較的あてはまりがよいと考えられる。あくまで比較的であってストレートに「あてはまっている」と言ってはいけないところが統計学の言い回しなところに留意したい。
一方ワークブックでは
この結論に対して、上側10%点より大きいか小さいかで判断している。これは、
- P-値を直接求めなくとも自由度に応じたカイ二乗上側パーセント点を使えばP-値の大小関係は分かる
- どのような有意水準であれば棄却できるのかできないのか
- 適合度検定において棄却するとは棄却しないとはどのような意味なのか
を学び取れというメッセージなのかもしれない。
付録:ソースコード
# グラフ作成用関数
fdraw <- function(df,from,to,col,add,chisq_stat, ylim = c(0, 0.2) ){
# 自由度 = df のカイ二乗分布
curve(dchisq(x, df), from, to, add = add, col = col, xlab = '', ylab = '', ylim=ylim)
# カイ二乗統計量
points(chisq_stat, 0, col=col)
# 上側確率の塗りつぶし
rng <- seq(chisq_stat,to,0.2)
segments(rng, 0, rng, dchisq(rng, df = df), col = col)
# P-値
print(paste("自由度",df,", カイ二乗統計量",chisq_stat, " のP-値は",
pchisq(chisq_stat, df, lower.tail = F)
))
}
# グラフ作成
fdraw(df=9, from=0, to=20, col='red',add = F, chisq_stat = 16.37)
fdraw(df=5, from=0, to=20, col='blue',add = T, chisq_stat = 2.27)
# カイ二乗分布上側確率表
qchisq( c(0.025, 0.05, 0.1,0.5,0.8) , df = 9, lower.tail = F)
qchisq( c(0.025, 0.05, 0.1,0.5,0.8) , df = 5, lower.tail = F)
pythonのvenv:仮想環境
仮想環境ってなに?
グローバル環境を汚さずにパッケージとかをインストールできる環境のこと 本家ドキュメントはこちら
仮想環境の作り方
python3 -m venv myenv
仮想環境の起動
axjack@axjack py % source myenv/bin/activate
pipが古いと怒られる
なぜデフォルトのpipが古いのかどうしたらupgradeできるのか、はよくわからない。。
(myenv) axjack@axjack py % pip list Package Version ---------- ------- pip 19.2.3 setuptools 41.2.0 WARNING: You are using pip version 19.2.3, however version 22.0.3 is available. You should consider upgrading via the 'pip install --upgrade pip' command.
言われた通りpipをupgrade
(myenv) axjack@axjack py % pip install --upgrade pip (myenv) axjack@axjack py % pip list Package Version ---------- ------- pip 22.0.3 setuptools 41.2.0
requiremenets.txtを使ってインストール
以前作った仮想環境のrequirements.txtを使って、
(myenv) axjack@axjack py % cat requirements.txt|head appnope==0.1.2 argon2-cffi==21.3.0 argon2-cffi-bindings==21.2.0 asttokens==2.0.5 attrs==21.4.0 backcall==0.2.0 bleach==4.1.0 cffi==1.15.0 cycler==0.11.0 debugpy==1.5.1
先ほど作った仮想環境にてpip installする。
pip install -r requirements.txt
pip listにて確認
(myenv) axjack@axjack py % pip list Package Version -------------------- ------- appnope 0.1.2 argon2-cffi 21.3.0 argon2-cffi-bindings 21.2.0 asttokens 2.0.5
うまくいったようだ。
jupyter notebookの起動はこんなかんじ
(myenv) axjack@axjack py % python -m notebook
デアクティベート
(myenv) axjack@axjack py % deactivate axjack@axjack py %
requirements.txtを作成する
(myenv) axjack@axjack py % python -m pip freeze > requirements.txt
venvをきれいにする
axjack@axjack py % python3 -m venv --clear myenv
参考にしたURL
- venvについて
- venvをクリアする
- pythonのimportのしくみ
- jupyter notebookをインストール
- pipの更新
昔の自分への追伸
あの時インストールしたnumpyとscipyは消しました。が、今回新規で作ったvenvの中でpip installしました。
(myenv) axjack@axjack lib % pwd /usr/local/lib (myenv) axjack@axjack lib % ls | grep python (myenv) axjack@axjack lib %
ランダムウォークと単位根
単位根を持つ時系列の例
を可視化、および階差をとって可視化してみる。時系列データ分析p.98 より。
一次元ランダムウォーク

一次元ランダムウォークの階差
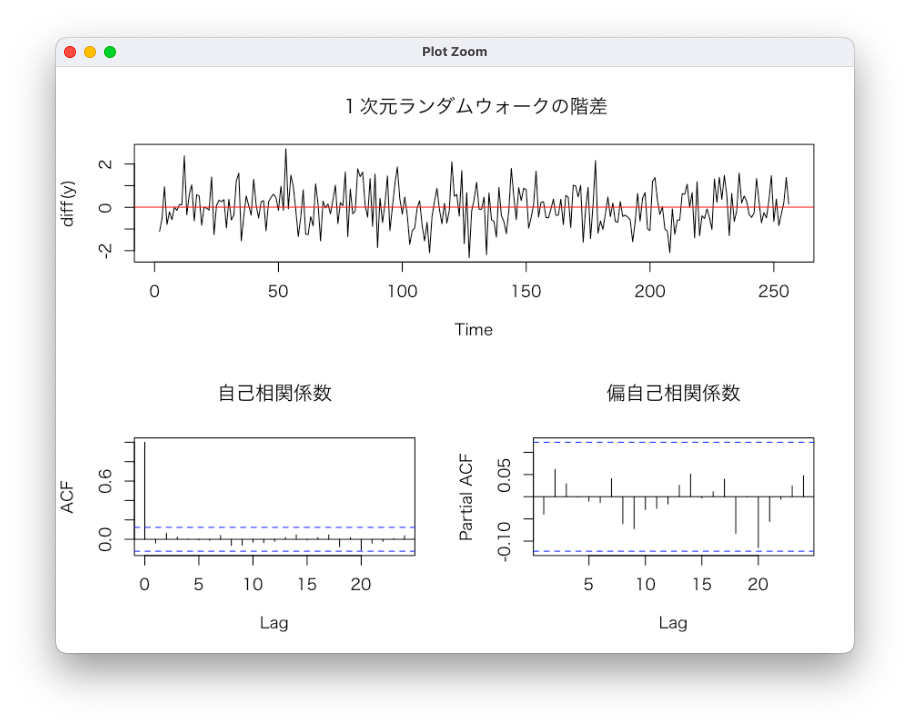
ADF検定の結果
ADF検定は単位根の有無を検定するもので、帰無仮説は「データ系列に単位根が存在する」である。
有意水準5%としてみると検定の結果、原系列(adf.test(y))の帰無仮説は棄却できなさそう。差分系列(adf.test(diff(y)))についてはp値 < 0.01より帰無仮説を棄却できそうである。
> adf.test(y)
Augmented Dickey-Fuller Test
data: y
Dickey-Fuller = -2.5377, Lag order = 6, p-value = 0.3494
alternative hypothesis: stationary
> adf.test(diff(y))
Augmented Dickey-Fuller Test
data: diff(y)
Dickey-Fuller = -5.6887, Lag order = 6, p-value = 0.01
alternative hypothesis: stationaryWarning message:
In adf.test(diff(y)) : p-value smaller than printed p-value
コード
# 単位根を持つ時系列データ
# p.98# 一次元ランダムウォーク
y <- cumsum( rnorm(2^8) )
y <- ts(y)
dev.off()
par(family="HiraKakuProN-W3")
split.screen(c(2,1))
split.screen(c(1,2), screen = 2)
screen(1);plot(y, main = "1次元ランダムウォーク")
abline(h = mean(y), col="red")
screen(3);acf(y, main = "自己相関係数")
screen(4);pacf(y, main = "偏自己相関係数")
dev.off()
par(family="HiraKakuProN-W3")
split.screen(c(2,1))
split.screen(c(1,2), screen = 2)
screen(1);plot(diff(y), main = "1次元ランダムウォークの階差")
abline(h = mean(diff(y)), col="red")
screen(3);acf(diff(y), main = "自己相関係数")
screen(4);pacf(diff(y), main = "偏自己相関係数")
ARとMAの自己相関係数と偏自己相関係数
統計学実践ワークブックのp.248の表を、グラフにて確かめる。表27.1の内容を一部引用。
| 選択モデル | 自己相関係数 | 偏自己相関係数 |
|---|---|---|
| AR(1) | ゆっくりと減衰 | 2次以降0 |
| MA(1) | 2次以降0 | ゆっくりと減衰 |
| AR(2) | ゆっくりと減衰 | 3次以降0 |
| MA(2) | 3次以降0 | ゆっくりと減衰 |
AR(1)とMA(1)

AR(2)とMA(2)

コード
rm(list=ls()) # 諸準備 dev.off() par(family="HiraKakuProN-W3") par(mfrow=c(2,2)) # AR(1)とMA(1) #### y1 <- arima.sim(n=1000, list(ar=c(0.5))) y2 <- arima.sim(n=1000, list(ma=c(0.8))) y1 |> acf(main="AR(1)の自己相関係数") y1 |> pacf(main="AR(1)の自己相関係数") y2 |> acf(main="MA(1)の自己相関係数") y2 |> pacf(main="MA(1)の偏自己相関係数") # AR(2)とMA(2) #### y3 <- arima.sim(n=1000, list(ar=c(0.4,0.2))) y4 <- arima.sim(n=1000, list(ma=c(0.8,0.4))) y3 |> acf(main="AR(2)の自己相関係数") y3 |> pacf(main="AR(2)の自己相関係数") y4 |> acf(main="MA(2)の自己相関係数") y4 |> pacf(main="MA(2)の偏自己相関係数")