単位根を持つ時系列の例
を可視化、および階差をとって可視化してみる。時系列データ分析p.98 より。
一次元ランダムウォーク

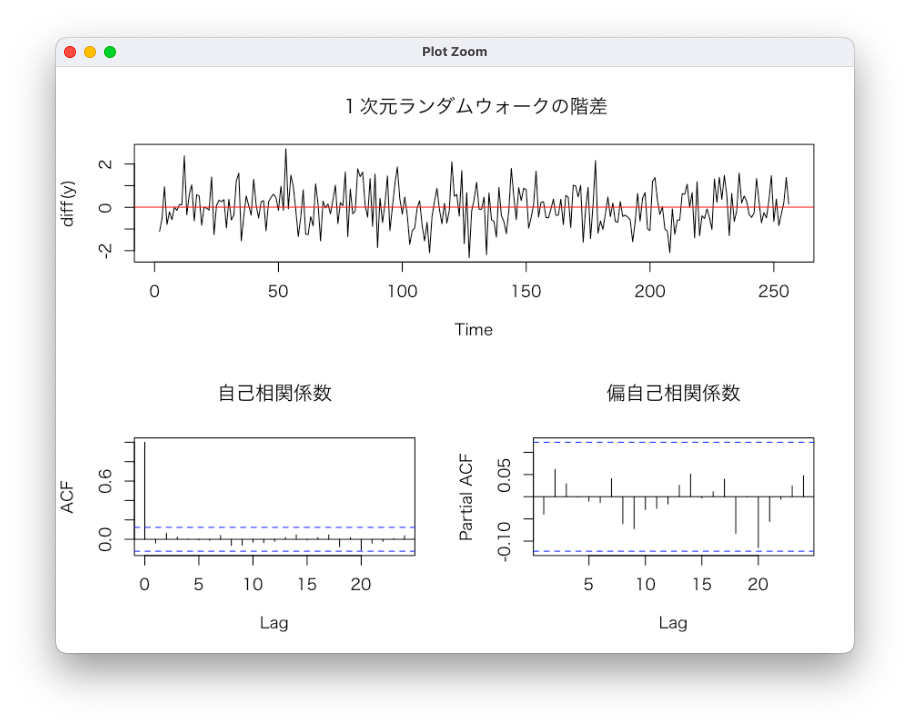
一次元ランダムウォークの階差
ADF検定の結果
ADF検定は単位根の有無を検定するもので、帰無仮説は「データ系列に単位根が存在する」である。
有意水準5%としてみると検定の結果、原系列(adf.test(y))の帰無仮説は棄却できなさそう。差分系列(adf.test(diff(y)))についてはp値 < 0.01より帰無仮説を棄却できそうである。
> adf.test(y)
Augmented Dickey-Fuller Test
data: y
Dickey-Fuller = -2.5377, Lag order = 6, p-value = 0.3494
alternative hypothesis: stationary
> adf.test(diff(y))
Augmented Dickey-Fuller Test
data: diff(y)
Dickey-Fuller = -5.6887, Lag order = 6, p-value = 0.01
alternative hypothesis: stationaryWarning message:
In adf.test(diff(y)) : p-value smaller than printed p-value
コード
# 単位根を持つ時系列データ
# p.98# 一次元ランダムウォーク
y <- cumsum( rnorm(2^8) )
y <- ts(y)
dev.off()
par(family="HiraKakuProN-W3")
split.screen(c(2,1))
split.screen(c(1,2), screen = 2)
screen(1);plot(y, main = "1次元ランダムウォーク")
abline(h = mean(y), col="red")
screen(3);acf(y, main = "自己相関係数")
screen(4);pacf(y, main = "偏自己相関係数")
dev.off()
par(family="HiraKakuProN-W3")
split.screen(c(2,1))
split.screen(c(1,2), screen = 2)
screen(1);plot(diff(y), main = "1次元ランダムウォークの階差")
abline(h = mean(diff(y)), col="red")
screen(3);acf(diff(y), main = "自己相関係数")
screen(4);pacf(diff(y), main = "偏自己相関係数")