統計学実践ワークブックのp.281あたりです。
期待値
は、
となる。
ギリギリですが合格しました。#統計検定準1級 pic.twitter.com/RVCSsQhUpB
— Satoaki Noguchi (@axjack_) 2023年2月11日
CBTってどんな感じなのかな?とあくまで試験の慣らし運転ぐらいの気持ちで受験に臨んだのですが、棚からぼたもち的な流れで合格していました。「合格」の文字が出た時は思わず「え?」と変な声が出ました(笑
配点ウェイトどうなってるんだ・・・?
統計学実践ワークブックを精読、行間を埋めるが中心でした。過去問はほとんど解いていないです。A4レポート用紙に式変形をひたすら書いて、はてなブログに勉強したことのまとめを書いてスマホにまとめを書いて、の繰り返しです。
準1級の勉強を通じて、なぜかLaTeX力がついた気がします。
数式変形のお供に。
本格的に学ぶには早すぎたかも?という意味で役に立ったか微妙でした。ただ、買って損はしないです。
確率変数の同時確率密度関数(joint pdf)を
とする。この時、
を
と変数変換(change of variables)することを考える。ただし、には逆変換が存在しそれを、
と表す。ここでヤコビアンを
とすると、変数変換後の同時確率密度関数は、
で表される(ここでは絶対値を表す)。
また、確率変数が独立でそれぞれの確率密度関数が
で与えられていれば、
となる。
さらに、同時確率密度関数を
で積分消去(integrate out, marginal, collapse)することで確率変数
の周辺確率密度関数(marginal pdf)を求めることができる。すなわち、
となる。
確率変数はそれぞれ独立に一様分布
に従うとする。確率密度関数
は
を用いて、および
で与えられる。
与えられた情報からまとめると、
なる不等式を得る。従って、に関する領域を書くと下記となる。

この図をw軸の視点で見ると、
となる。

とする。この時、C(A)の任意のベクトルとN(A')の任意のベクトルは直交する。
x ∈ C(A), y ∈ N(A')を任意に取る。ベクトルが直交することを示すには内積が0となることを確認すれば良い。なお、小文字のoを零ベクトルとする。
すると、
となってy'x = x'y = 0が示せた。
したがって、C(A)の任意のベクトルとN(A')の任意のベクトルは直交する。
□
d <- c(1:10)
Fn <- ecdf(d)
plot(Fn)knots(Fn)
Gn <- stepfun(d,c(1,3,2,5,4,7,3,3,4,2,1))
plot(Gn)
QittaのR言語記事を散策していたら@roadricefieldさんの面白い記事があったので、自分でも解いてみることにしました。
極値を求める関数を作成する問題。
extremum_detector <- function(d, k){
# 補助関数
f <- function(a,k){
judge <- rep(c(1,-1),each=(k-1)/2)
sdf <- sign(diff(a))
all(sdf == judge)||all(sdf == rev(judge))
}
if(k < 3 || k %% 2 == 0) stop()
# extremum pointを返す
which(apply(embed(d,k),MARGIN=1,f,k)) + (k-1)/2
}
5点近傍での極値
dev.off() data <- c(1, 2, 3, 2, 1, 0, 1, 0, -1, 2, 3, 2, 1) extremum.points <- extremum_detector(data, 5) plot(data, type="b") points(extremum.points, data[extremum.points],col = "red",pch=16)

3点近傍での極値
dev.off() data <- c(1, 2, 3, 2, 1, 0, 1, 0, -1, 2, 3, 2, 1) extremum.points <- extremum_detector(data, 3) plot(data, type="b") points(extremum.points, data[extremum.points],col = "red",pch=16)

embed関数なるものを使うと、系列を左から個ずつスライドして取り出すことができて便利(ただし順番が逆になる点のみ注意)
> letters[1:12]
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l"
> embed(letters[1:12],4)
[,1] [,2] [,3] [,4]
[1,] "d" "c" "b" "a"
[2,] "e" "d" "c" "b"
[3,] "f" "e" "d" "c"
[4,] "g" "f" "e" "d"
[5,] "h" "g" "f" "e"
[6,] "i" "h" "g" "f"
[7,] "j" "i" "h" "g"
[8,] "k" "j" "i" "h"
[9,] "l" "k" "j" "i"
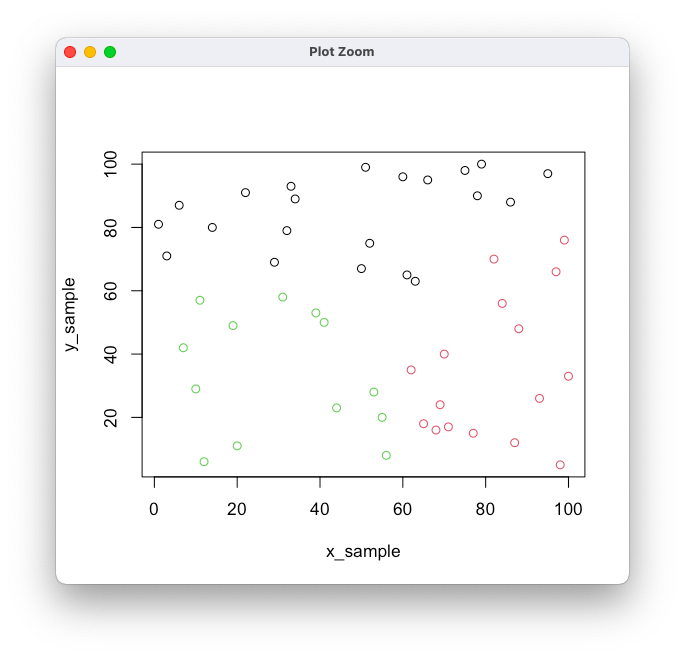
k-meansクラスタリングを実装する。
my_kmeans <- function(x = x_sample, y = y_sample, k = 3){
# # 初期クラスタを選択
# cent_ind <- sample(seq_along(x), k, replace = FALSE)
# # 初期セントロイドたち
# cent <- cbind(x[cent_ind], y[cent_ind])
# cent <- cbind(c(91,57,41),c(26,61,14))
cent <- sample( (min(x,y)):(max(x,y)), k * 2, replace = FALSE) |> matrix(nrow = k)
i <- 0
while(1){
# セントロイドからの距離が最小となるような所属を求める
M <- rbind(cent, cbind(x,y)) |> dist() |> as.matrix()
belong <- M[-(1:k),1:k] |> apply(MARGIN = 1, which.min)
# 新しいセントロイド
cent_new <- cbind(tapply(x, belong, mean), tapply(y, belong, mean))
i <- i+1
cost <- sum((cent_new - cent)^2)
print(paste("iter = ",i,", cost = ", cost))
# costが1より小さかったらループ終了
if ( cost < 1 ) break
# セントロイドの更新
cent <- cent_new
}
# 所属を返す
return( belong |> as.numeric() )
}
dev.off(); set.seed(2022) x_sample <- sample(1:100, 50, replace = FALSE) y_sample <- sample(1:100, 50, replace = FALSE) clst <- my_kmeans(x_sample, y_sample, k = 3) plot(x_sample, y_sample, col = clst )