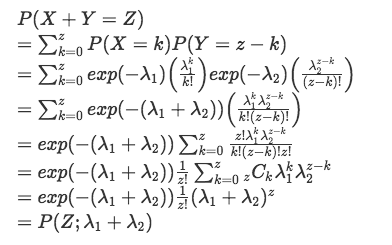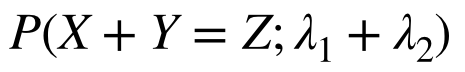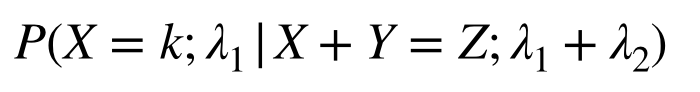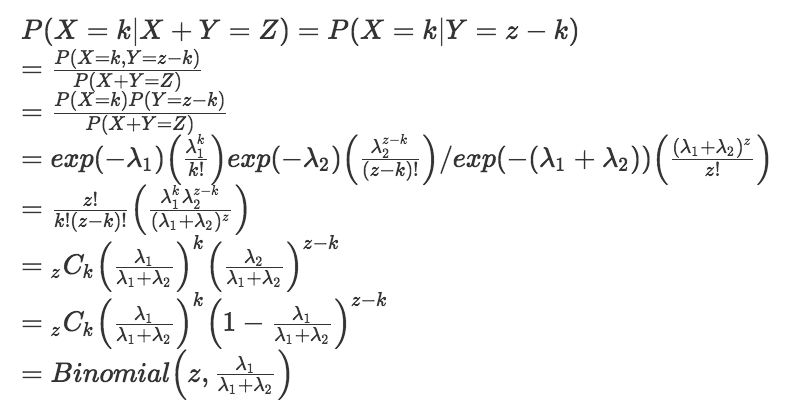Rでロジスティック回帰
テーマはロジスティック回帰。問題文に記載された出典を調べると、Risk Analysis of the Space Shuttle: Pre-Challenger Prediction of Failureがヒットするので、このデータを用いれば再現が出来る(のだろうか)。ひとまずやってみると、
データの読み込み
# Field Erosion or blowby ####
yF <- c(0,1,0,0,0,0,0,0,1,1,1,0,0,2,0,0,0,0,0,0,1,0,1)
TD <- ifelse(yF > 0, 1, 0)
Temperature <- c(66,70,69,68,67,72,73,70,57,64,70,78,67,53,67,75,70,81,76,79,75,76,58)
r <- glm(TD ~ Temperature, family = binomial(link = logit))
結果
> summary(r)
Call:
glm(formula = TD ~ Temperature, family = binomial(link = logit))
Deviance Residuals:
Min 1Q Median 3Q Max
-1.0665 -0.7679 -0.3844 0.4541 2.2047
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 14.9246 7.4235 2.010 0.0444 *
Temperature -0.2302 0.1087 -2.117 0.0343 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 28.267 on 22 degrees of freedom
Residual deviance: 20.511 on 21 degrees of freedom
AIC: 24.511
Number of Fisher Scoring iterations: 5
やや違うがおおよそ問題文の出力結果と合致している。
作図
plot(Temperature, TD)
points( Temperature,fitted(r), col='red')

問10の小問を解く
[1][2]
y_i は 互いに独立な確率変数Y_i の実現値であり、Y_i は (ア) に従う。
π_i( 0 < π_i < 1 ) について、構造式(イ) を仮定する。
とある。ロジスティック回帰なのでY_iはポアソン分布に従い、構造式(リンク関数?)はロジットなのでlog( (π_i / ( 1 - π_i) ) =である。
[3]
0 = 15.0429 - 0.2322 x_i をx_i について解くと、x_i = 64.78423772
[4]
確率を求めるのでロジットではなくロジスティック関数に戻して解いてみる。すると、π_i = 1 / ( 1 - exp( - (15.0429 - 0.2322x_i) ) ) で x_i <- 31 としてπ_iを求めれば良い。結局、
> 1/(1+exp(-7.8447))
[1] 0.9996083
となる。
終わりに
試験㆗、「聞いたことあるけど自分で解いたことないんだよなぁ、でも解けたら応用範囲が広そうだなぁ」と思っていた問題の1つ。